The Deep Dive into Disconnected Care Systems: Technology, Operations, and Revenue Impact
Your agency runs on eight different systems. You’ve accepted this as normal. But it’s not.
It’s an architectural failure.
Most agencies don’t realize the scope of the problem because they’ve never seen what “connected” looks like. They only know the fragmented reality they’re operating in.
This deep dive will show you exactly how disconnected systems work (or fail to work), why traditional integration approaches don’t fix the problem, and why this technical architecture issue has cascading operational and financial consequences.
Mapping the Disconnection: How Eight Systems Become a Tangled Web
Let’s map out what “disconnected” actually looks like in a typical care agency.
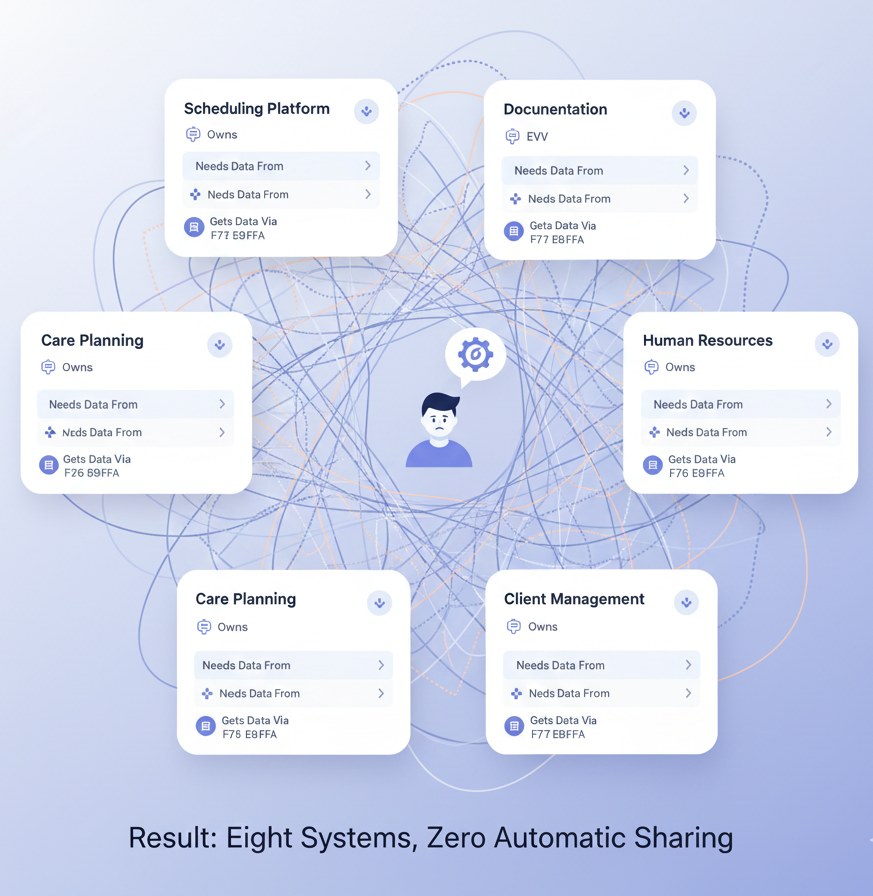
System #1: Scheduling Platform
- Owns: Caregiver schedules, client assignments, availability
- Data it needs from: Caregiver credentials (System #5), billing parameters (System #2), client care plans (System #7)
- How it gets that data: Manual entry, weekly file exports, human intervention
System #2: Billing/Revenue Cycle Platform
- Owns: Claims, payments, A/R, insurance verification
- Data it needs from: Scheduling data (System #1), documentation (System #7), compliance status (System #5)
- How it gets that data: Manual export/import, periodic reconciliation, guess-and-check
System #3: EVV (Electronic Visit Verification) App
- Owns: Visit timestamps, caregiver location data, clock-in/clock-out records
- Data it needs from: Scheduled visits (System #1), caregiver identification (System #6)
- How it gets that data: Automatic for some data, manual for others, fragmented approach
System #4: Documentation/Care Notes Platform
- Owns: Care notes, progress notes, incident reports, care plans
- Data it needs from: Caregiver information (System #6), client information (System #8)
- How it gets that data: Manual entry, slow integrations, often duplicated
System #5: Compliance Tracker
- Owns: Credentials, certifications, training records, audit trails
- Data it needs from: Caregiver schedules (System #1), care notes (System #4)
- How it gets that data: Completely manual, requires manual verification
System #6: Human Resources/Applicant Tracking
- Owns: Caregiver profiles, hiring records, background checks, onboarding checklists
- Data it needs from: Everything (for complete employee records)
- How it gets that data: Manual entry only—incredibly fragmented
System #7: Care Planning System
- Owns: Care plans, client preferences, family communication
- Data it needs from: Billing parameters (System #2), caregiver schedules (System #1)
- How it gets that data: Manual updates, slow communication, often outdated
System #8: Client/Patient Management
- Owns: Demographic information, insurance data, admission/discharge records
- Data it needs from: All other systems (comprehensive view)
- How it gets that data: Manual entry, relies on other systems not changing data behind its back
Result: Eight systems, zero automatic sharing.
The Data Flow Problem: Information Stuck in Silos
When information is stuck in silos, simple tasks become complex.
Example 1: A Caregiver’s Credential Expires
What should happen:
- System detects expiration date approaching
- System alerts the caregiver automatically (email, SMS, in-app notification)
- System provides renewal resources and deadline
- System updates scheduling to prevent assignments to non-credentialed staff
- System flags in billing to hold payment until credential is renewed
- System completes
What actually happens:
- Compliance coordinator manually checks each caregiver’s credential dates weekly
- Compliance coordinator looks at when the credential expires
- Compliance coordinator sends a manual email to the caregiver
- Caregiver may or may not read the email
- Caregiver may or may not take action
- Days/weeks pass
- Scheduling system doesn’t know the credential expired (different system)
- Scheduler assigns the caregiver to visits anyway
- EVV system clocks the visits with an expired credential
- Billing system submits claims with an uncredentialed caregiver
- Payer rejects claims or requests claw-back
- Compliance coordinator discovers the problem during month-end reconciliation
- Weeks of administrative work to fix
- Client care may have been compromised
- Revenue is lost
The difference: One system can prevent a crisis. Eight systems guarantee it.
Integration Failure Modes: Why Traditional Approaches Don’t Work
You’ve probably already tried to “fix” the disconnection problem. And it didn’t work.
Here’s why:
API Integration Limitations
APIs (Application Programming Interfaces) are how systems technically talk to each other. In theory, you can connect any two systems via API.
In practice:
1. APIs are bidirectional but systems are designed uni-directionally
- Scheduling system sends data to billing
- But billing system doesn’t feed updates back to scheduling
- Data goes one direction, creating inconsistency
2. APIs have rate limits and latency
- Data doesn’t flow in real-time; it flows in batches
- Batch jobs run every 4-6 hours
- For 8 hours, your systems are out of sync
- Manual work fills the gap
3. APIs break when vendors update
- Vendor A updates their API
- Your integration breaks
- You either: (a) manually fix it, (b) hire a developer to fix it, or (c) go back to manual workarounds
- This happens quarterly
4. APIs don’t solve data model mismatches
- System A stores “hours worked” as a decimal
- System B stores it as hours/minutes
- The API converts between them, but conversions are lossy
- You lose precision and accuracy
Middleware and Integration Platforms
Some agencies try tools like Zapier or Make to create connections between systems. These are middleware tools—a layer between the systems that tries to translate between them.
They have the same problems as APIs, plus:
- Added complexity (more system to manage)
- Slower data flow (extra hop)
- Single point of failure (if middleware goes down, everything stops)
- Ongoing maintenance (every time either connected system updates)
The Fundamental Problem: Multiple Data Models
The real issue with traditional integration: Each system has its own data model.
Scheduling system thinks of “visits” as time blocks.
Billing system thinks of “visits” as billable units.
EVV system thinks of “visits” as location-timestamped events.
Documentation system thinks of “visits” as clinical episodes.
When you try to integrate these, you’re translating between four different definitions of the same concept. Translations are lossy. Details get lost. Accuracy suffers.
The only solution is one unified data model. Not four systems with translation layers. One system, one definition.
The Middleware Burden: You Are Becoming the Human API
Because the systems won’t integrate properly on their own, you’ve become the integration.
Your administrators are spending 30-40% of their time as human APIs:
- Translating between system formats
- Manually moving data from one place to another
- Reconciling when systems disagree
- Creating manual workarounds when integrations fail
This is administrative overhead that literally serves no business purpose. You’re not improving care. You’re not growing revenue. You’re not serving patients. You’re just moving data between systems that should be moving it themselves.
And you’re paying for the privilege:
- Software costs: $20,000-$40,000 annually (for the privilege of fragmentation)
- Labor costs: $150,000-$200,000 annually (for being the human API)
- Total fragmentation tax: $170,000-$240,000 annually
Cascading Failures: One System’s Error Multiplies Across Eight
When systems are disconnected, one error cascades through everything.
Example: A Scheduling Error
- Scheduler enters wrong caregiver credentials in the scheduling system (mistake: 5 seconds)
- Scheduled caregiver shows as unqualified, but error isn’t caught immediately
- EVV system doesn’t know about the error (different system)
- Caregiver clocks in for a visit she’s not qualified for
- Documentation system doesn’t catch it (doesn’t know qualification requirements)
- Billing system submits a claim with an unqualified caregiver
- Compliance system doesn’t flag it (doesn’t see scheduling data)
- A week later, the error is discovered during reconciliation
- By then: You’ve submitted 7 unauthorized claims, the caregiver has provided unqualified care, compliance is at risk
In an integrated system, the error would be caught within seconds. The system would either: (a) prevent the incorrect entry, or (b) immediately flag the inconsistency across all downstream systems.
But with eight disconnected systems, errors propagate.
API Limitations, HIPAA Constraints, and Technical Realities
You might think: “Why don’t vendors just open their APIs fully and let systems talk to each other?”
Three reasons:
1. API Development is Expensive
Building a robust API that handles bidirectional data flow, rate limiting, error handling, and ongoing maintenance costs money.
Vendors consider that cost against their revenue. If the API costs $500,000 to build but only saves 10% of customers from leaving, the ROI doesn’t justify the investment.
But if maintaining customer lock-in (through fragmentation) is more profitable than building APIs, guess what wins?
2. HIPAA Compliance Constraints
Healthcare data is regulated. Every time data moves between systems, there are HIPAA implications:
- Audit trails must be maintained
- Access controls must be enforced
- Encryption must be verified
- Data minimization rules must be followed
Vendor A could build an API to Vendor B, but now Vendor A is responsible for Vendor B’s security. Vendor A doesn’t want that liability.
So instead of building tight integrations, vendors maintain silos. Each company is responsible for their own security. Data moves manually (and documentation of that manual transfer serves as audit trail).
3. Competitive Advantage
If Vendor A integrates deeply with Vendor B, and then Vendor C launches a better product, customers can easily switch to Vendor C.
But if Vendor A is tightly integrated with 8 other products, switching costs are enormous. Customer lock-in is high.
Vendors optimize for lock-in, not integration.
The Operational Debt: Disconnection as Hidden Technical Liability
Every fragmented system is technical debt.
Technical debt is the cost you pay today for choices you made in the past. It compounds over time.
Your current technical debt from fragmentation:
Immediate Costs:
- Labor hours spent on manual integration (40+ hours/week)
- Software costs for multiple systems ($20,000-$40,000/year)
- Errors from manual data transfer (lost revenue, compliance risk)
Medium-term Costs:
- Caregiver turnover from admin-heavy systems (loss of institutional knowledge)
- Slower scaling (can’t grow without adding admin overhead)
- Audit findings (compliance gaps from manual processes)
Long-term Costs:
- Data loss (if a system goes out of business)
- Compliance liability (if manual processes fail)
- Competitive disadvantage (competitors using better systems grow faster)
The only way to eliminate technical debt is to stop incurring it. And the only way to stop incurring it is to move to a unified system.